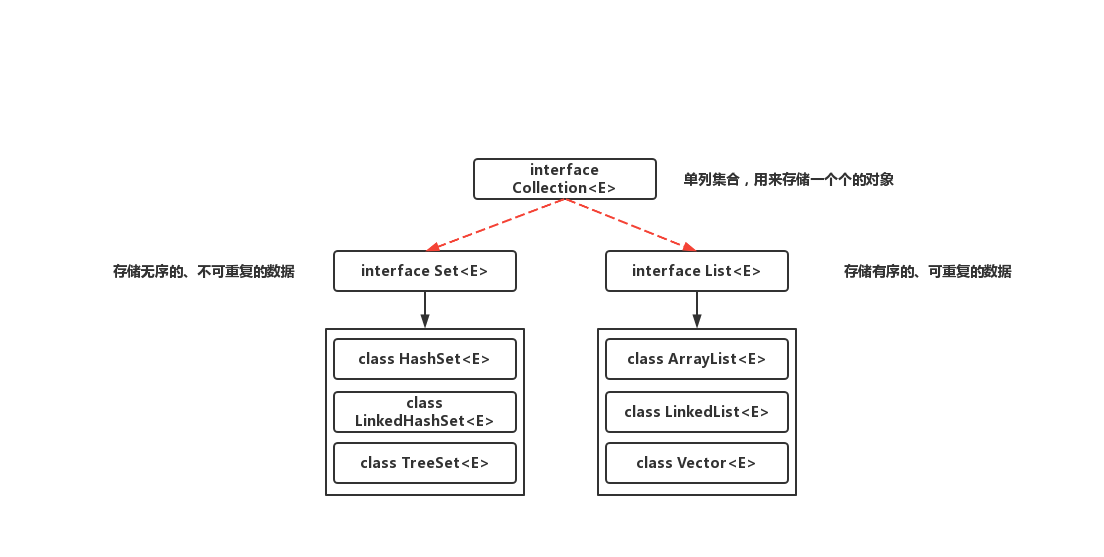
以下描述引用于onJava 8: 集合(Collection) :一个独立元素的序列,这些元素都服从一条或多条规则。List 必须以插入的顺序保存元素, Set 不能包含重复元素, Queue 按照排队规则来确定对象产生的顺序(通常与它们被插入的顺序相同)
关于数组的概述
数组在存储多个数据方面的特点: ① 一旦初始化以后,其长度就确定了; ② 数组一旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。比如:String[] string;int[] int。
数组在存储多个数据方面的缺点: ① 一旦初始化以后,其长度就不可修改。 ② 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不高。 ③ 获取数组中实际元素的个数的需求,数组没有现成的属性或方法可用。 ④ 数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
上图为jdk 8中的ArrayList部分源码,在执行语句:ArrayList list = new ArrayList();时;源码中并没用直接创建长度为10的数组,而是先将数组初始化为空:Object[] elementData;在第一次调用list.add(123)方法时,ArrayList才会去创建对应长度内的数组(若第一次add的数据的长度大于默认长度,那么数组的长度会定义为该数据的长度;若小于,则创建长度为10的数组),并将数据123添加到elementData数组中。
/** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; }
//此条件是为了处理溢出的情况 //比较计算出的新长度与MAX_ARRAY_SIZE:ArrayList允许的最大长度 if (newCapacity - MAX_ARRAY_SIZE > 0) //如果扩容后的长度大于允许的最大长度,调用hugeCapacity方法 //根据hugeCapacity方法源码可知,当minCapacity > MAX_ARRAY_SIZE时,将返回Integer.MAX_VALUE赋给新长度 newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: //调用Arrays.copyOf方法,传入旧的数组、扩容后的长度;返回一个拥有新的长度的数组(原有值不变) elementData = Arrays.copyOf(elementData, newCapacity); }
* for typical instances of the class, this loop: * * for (int i=0, n=list.size(); i < n; i++) * list.get(i); * * runs faster than this loop: * * for (Iterator i=list.iterator(); i.hasNext(); ) * i.next(); *
public static <T> List<T> synchronizedList(List<T> list) { return (list instanceof RandomAccess ? new SynchronizedRandomAccessList<>(list) : new SynchronizedList<>(list)); }
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> { private static final long serialVersionUID = -7754090372962971524L;
public boolean equals(Object o) { if (this == o) return true; synchronized (mutex) {return list.equals(o);} } public int hashCode() { synchronized (mutex) {return list.hashCode();} }
public E get(int index) { synchronized (mutex) {return list.get(index);} } public E set(int index, E element) { synchronized (mutex) {return list.set(index, element);} } public void add(int index, E element) { synchronized (mutex) {list.add(index, element);} } public E remove(int index) { synchronized (mutex) {return list.remove(index);} }
public int indexOf(Object o) { synchronized (mutex) {return list.indexOf(o);} } public int lastIndexOf(Object o) { synchronized (mutex) {return list.lastIndexOf(o);} }
public boolean addAll(int index, Collection<? extends E> c) { synchronized (mutex) {return list.addAll(index, c);} }
public ListIterator<E> listIterator() { return list.listIterator(); // Must be manually synched by user }
public ListIterator<E> listIterator(int index) { return list.listIterator(index); // Must be manually synched by user }
public List<E> subList(int fromIndex, int toIndex) { synchronized (mutex) { return new SynchronizedList<>(list.subList(fromIndex, toIndex), mutex); } } }
int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work